
Đây là bài giải thích về concept Unicode – encode – decode, không phải bài hướng dẫn cách làm. Đây là kiến thức chung cho mọi người làm phần mềm chứ không riêng gì dev hay tester, do đó kiến thức này là kiến thức “phải có” đối với chúng ta, những software testers ngày ngày tìm kiếm bug.
I. Vấn đề nổi cộm
- Bạn nhận được dòng tin nhắn “???? ????? ?????” khi bạn sử dụng những ngôn ngữ có dấu hoặc ký tự đặc biệt. Ví dụ: Mình hay nhìn thấy cái này của Bluezone những ngày dịch Covid cuối năm.

- Bạn không hiểu vì sao mà cùng 1 cái mặt cười (:D) mà mỗi app lại làm khác nhau.

II. Cách máy tính làm việc với ký tự
Ai cũng biết, máy tính làm việc dựa vào dựa vào những con số 0, 1. Tùy vào độ dài của những con số này mà sẽ lưu trữ nhiều hoặc ít thông tin. Ví dụ:
1 byte = 8 bits (8 ô vuông chứa 0 và 1)

Thế giả sử 1 byte này mà đại diện cho 1 ký tự thì sẽ có 2^8 = 256 ký tự.
Và ASCII ra đời, với việc sử dụng 7 bits cho 1 Character, ta có 2^7 = 128 ký tự (00-126), gồm 2 loại: control characters (ví dụ như tiếng beep) và printable characters (in được ra giấy).
Ví dụ: ký tự 65 là A, 97 là a.
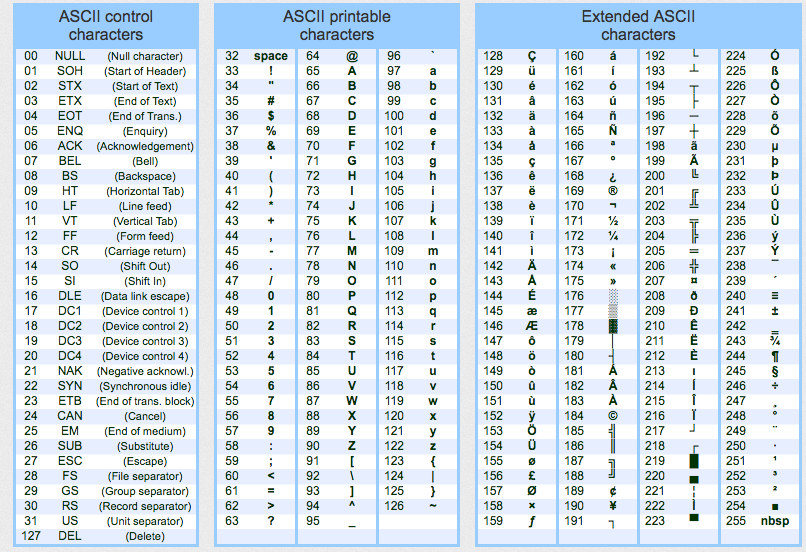
Dễ thấy, bảng ASCII trên chỉ phù hợp cho những ký tự của tiếng Anh, còn nhiều ký tự như tiếng Trung, tiếng Nhật, tiếng Thái…không có. Vậy thì làm thế nào?
Unicode ra đời để xử lý bài toán như vậy, nó mang theo 1 concept mới “Code Point”
Mỗi 1 code point sẽ đại diện cho 1 character: Ví dụ: +U0254. Tập hợp các ký tự này gọi là Unicode character set.
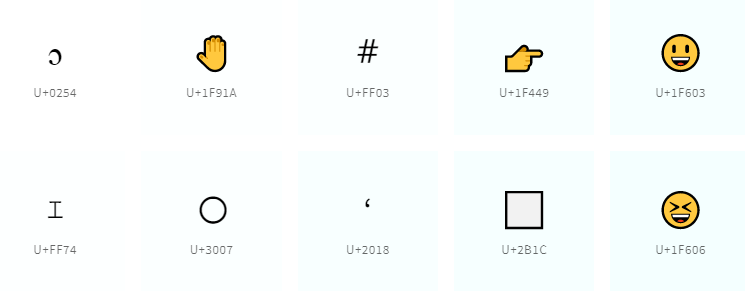
Ta dễ nhận thấy: Code point sẽ là trung gian giữa ký tự và số lượng bits, byte của máy tính. Và do đó nó là 1 khái niệm trừu tượng, đối với con người và máy tính. Để chuyển đổi giữa bytes <–> code point, ta cần quá trình decode và encode.

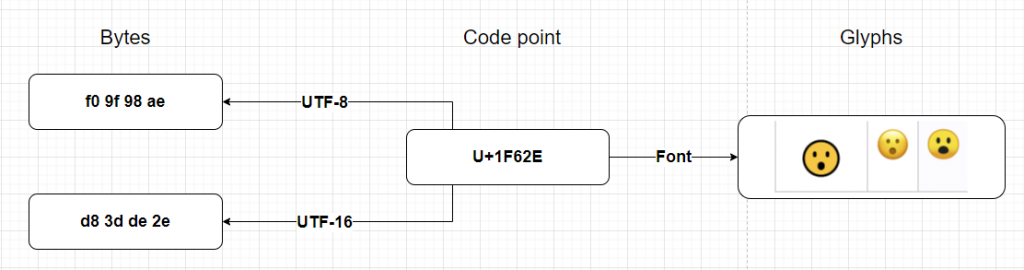
UTF-8 | UTF-16 … là những bộ rules hay thuật toán để thực hiện việc encode, chuyển đổi code points thành những dãy (1->4) bytes.
Sẽ ra sao nếu bạn thực hiện việc encode bằng UTF-8 mà lại decode bằng ISO-8859-1?
- Sẽ hiển thị được những ký tự mà 2 cùng có cách encode giống nhau (ví dụ những printable ký tự của bảng ASCII)
- Không hiển thị được những ký tự khác và nó được thay thế bằng những dấu ??? như Bluezone ở phía trên.
III. Tổng kết
Mình đã cố gắng viết ngắn gọn nhất có thể rồi, còn nhiều thứ phức tạp và chi tiết hơn, mọi người có thể đọc từ các nguồn dưới đây. Nếu bạn thấy hay, đừng ngại ngần chia sẻ bài viết, nếu bạn thấy sai ở đâu, hãy để làm comment nhé để mình hoàn thiện. Thanks
https://towardsdatascience.com/processing-text-with-unicode-in-python-eacc226886cb